Demographic identifier
Overview
Ever wondered how to engage more diversity in communications? This toolkit identifies gender, age and ethnic communities on Twitter with computer vision and analyzes what makes a message inclusive using neural sentence embeddings.
Examples
 Semantic similarity of randomly sampled Tweets about legislation, innovation, and clean water shows the ability of the Universal Sentence Encoder to cluster Tweets by meaning.
Semantic similarity of randomly sampled Tweets about legislation, innovation, and clean water shows the ability of the Universal Sentence Encoder to cluster Tweets by meaning.
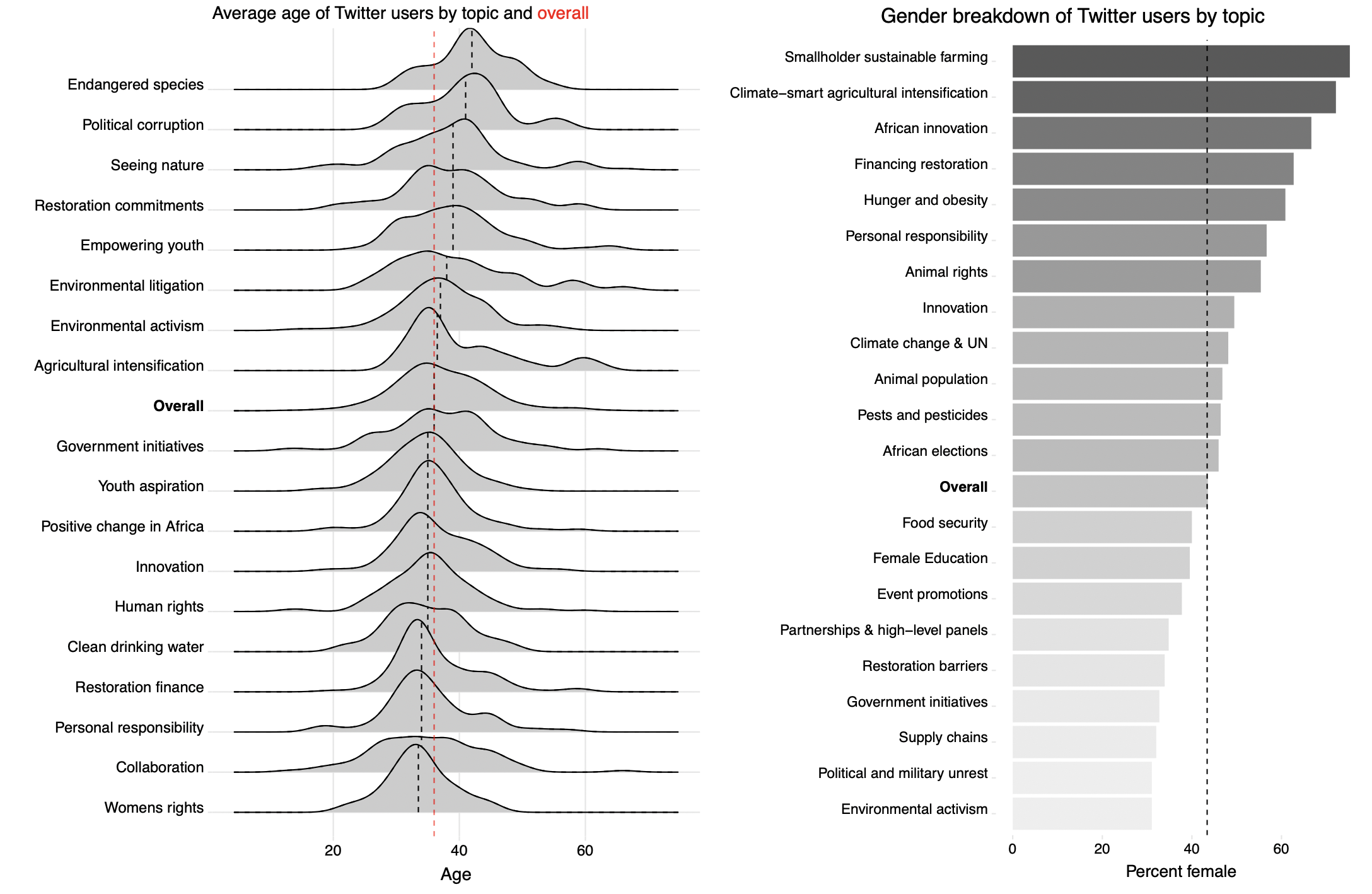 Distribution of select topics by age (left) and gender (right) allows the user to understand how certain demographics engage with different messages.
Distribution of select topics by age (left) and gender (right) allows the user to understand how certain demographics engage with different messages.
Installation
This Python + R toolkit requires a Python 3.6 environment. The dependencies can be installed with
$ pip3 install -r requirements.txt
The R requirements tidyverse, gender, plyr, and jsonlite can be installed with
install.packages(c('tidyverse', 'gender', 'plyr', 'jsonlite'))
Use
1. Data acquisition
Input data should be in the form of a compressed streaming JSON returned from the Twitter API. The download_data.R script will identify all user profile images in the API results and download every image to the img folder.
2. Age and gender identification
Running, in order, the age-gender-image.py and gender_age.R scripts will create a .CSV in the results folder estimating the age and gender of each twitter handle.
3. Ethnicity identification
Ethnicity is estimated using the Python package ethnicolr which uses character-level RNN to predict race from first and last name. After install, ethnicity can be estimated using the following bash script
pred_wiki_name -o {output.csv} -l last.name -f first.name {input.csv}
We have tested ethnicity identification using computer vision, but without training a model from scratch - which we do not have the labelled data for - there does not seem to be any deployable alternatives.
Methodology
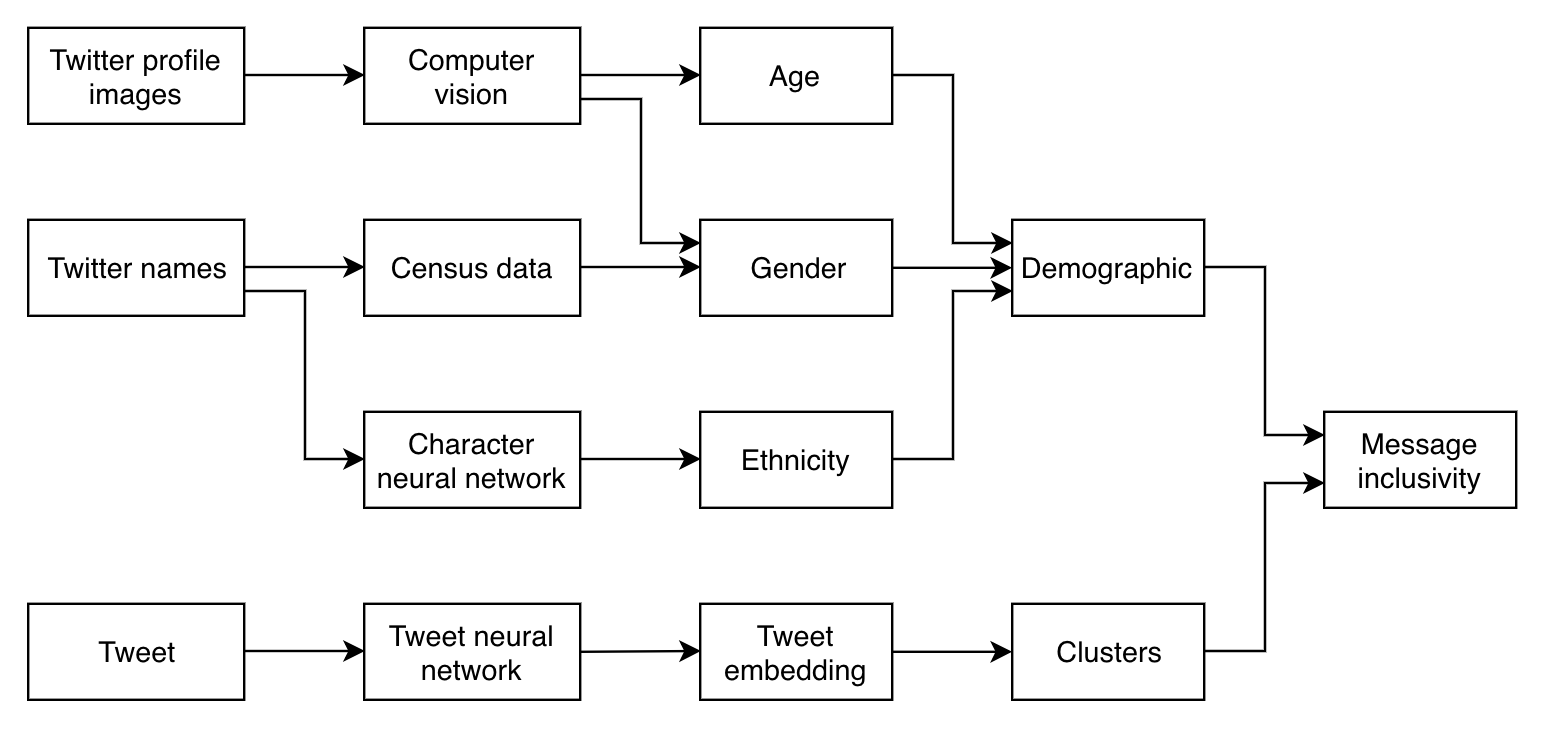
Model architecture
Gender is estimated using a combination of computer vision and U.S. census data. The gender R package matches first names to gender proportions in the U.S. census. Gender and age were also estimated using a pre-trained WideResNet architecture network trained on 500,000 photographs labelled by age and gender.
The mean error is 3 years for age, and the accuracy rate for gender is 95%. These estimates are validated by matching the name, when available, to US census data on gender percentiles by first name. In more than 95% of cases, these two estimates match. When they do not, the highest confidence estimate is used as the gender prediction. Pairing these two modes of estimating gender allows an estimate where only one of the two data sources are available (User image containing a face, or first name).
The WideResNet architecture automatically identifies and disregards Twitter handles that do not have profile pictures containing faces. When there is more than one face, the Twitter handle is assigned the demographic most likely to belong to the name associated with the handle. Name-based identification also identifies names that are not real names, which are about 15% of Twitter handles. Twitter profiles that have neither a real name nor have a facial photograph are disregarded.
Text cleaning
Tweets often are not grammatically correct, have spelling errors, and have hashtags. The Python module ekphrasis is used to clean the Twitter text data, using a language model (FastText) trained on 1 billion tweets. This automatically corrects common spelling errors, like elongating words (ex: “wooooooow”), hashtag phrases (ex: “#savetheplanet” -> “save the planet”), and converts user mentions to a single unique token.
The spell-correction.py script will take an input CSV of tweets and write cleaned output to a CSV in the data/processed folder.
Semantics and topics
Differences in semantics between demographic groups can be modelled with neural variational inference or sentence embeddings that do not rely on continuous sentences, such as doc2vec. With large amounts of training data, semantics may be modelled by taking the l2 norm of the summation of word level multilingual embeddings, such as MUSE.