Multi-task text classification
Overview
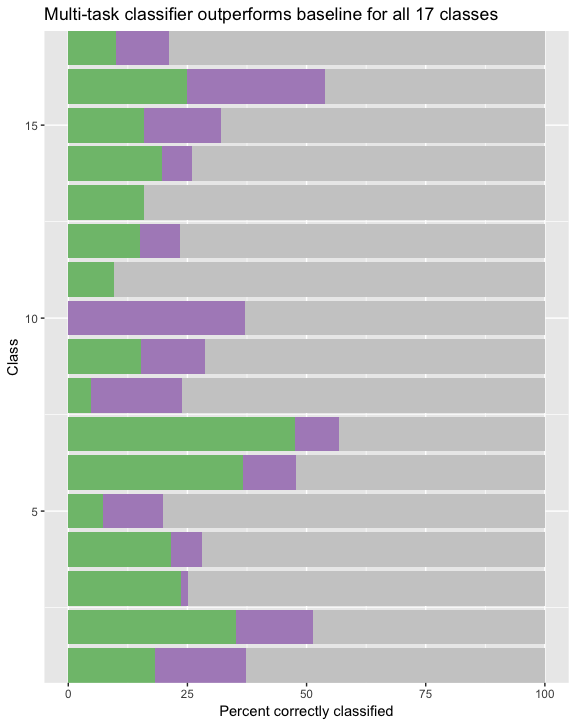
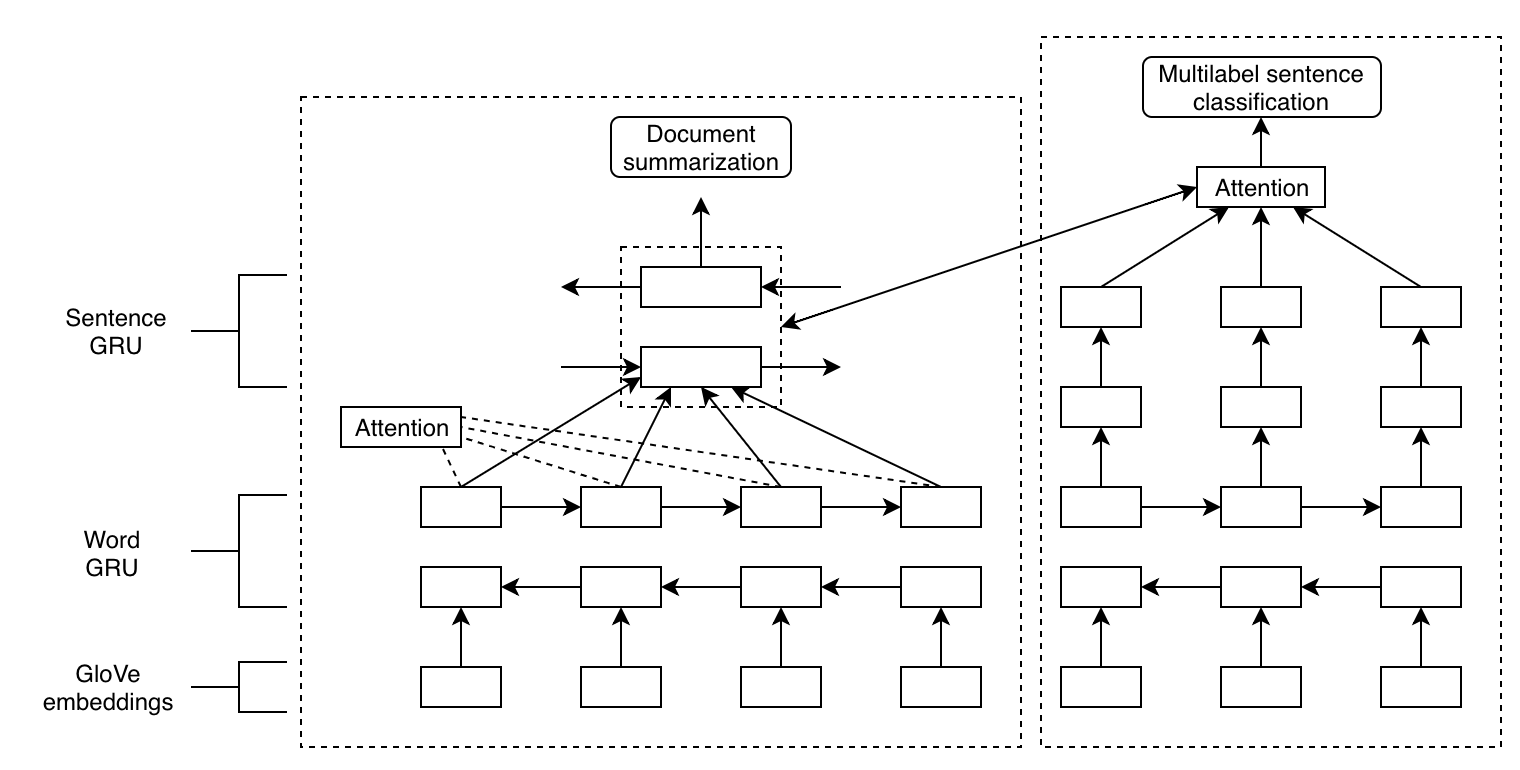
This architecture predicts the multilabel classification of sentences by leveraging context-specific information construed from their source documents. By employing multi-task training of an extractive summarizer and an RNN-based classifier, this architecture improves summarization and classification accuracy by 50% and 75%, respectively, relative to RNN baselines.
Model formula
Installation
Python 3.6 is required and the dependences can be installed with:
python setup.py --install
Usage
python main.py --epochs {} --training_size {} --batch_size {}
Data
Training data is sourced from Resource Watch, a research project from the World Resources Institute. Sentence relevance to 17 separate classes were hand-coded for 155 environmental policies (~4,000 pages) by a team of domain experts. 8,922 of the ~50,000 sentences were classified as relevant.
Steps
1. General data preparation
Sentences are tokenized with a max word count of 10,000 and encoded with pre-trained GloVe embeddings. Contractions and punctuation are treated as their own word. Sentences are padded to 50 words.
2. Extractive summarization
Data is structured in a 3-dimensional array of the form (docs, sentences, words).
3. Multilabel sentence classification
Under-represented data classes are augmented with psuedo-random bootstrapping such that the range of class distribution falls within a tunable parameter. A bidirectional GRU and attention with context clayer are used to classify each sentence, with a l2 regularization and recurrent dropout of 0.3. Model fit is measured using top k accuracy on a 20% validation split.
Results